Introduction
There have been a number of recent Infinispan 7.0 Map/Reduce performance related improvements that we were eager to test in our performance lab and subsequently share with you. The results are more than promising. In the word count use case, Map/Reduce task execution speed and throughput improvement is between fourfold and sixfold in certain situations that were tested.
We have achieved these improvements by focusing on:
- Optimized mapper/reducer parallel execution on all nodes
- Improving the handling and processing of larger data sets
- Reducing the amount of memory needed for execution of MapReduceTask
Performance Test Results
The performance tests were run using the following parameters:
- An Infinispan 7.0.0-SNAPSHOT build created after the last commits from the list were committed to the Infinispan GIT repo on May 9th vs Infinispan 6.0.1.Final
- OpenJDK version 1.7.0_55 with 4GB of heap and the following JVM options:
- -Xmx4096M -Xms4096M -XX:+UseLargePages -XX:MaxPermSize=512m -XX:NewRatio=3 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
- Random data filled 30% of the Java heap, and 100 random words were used to create the 8 kilobyte cache values. The cache keys were generated using key affinity, so that the generated data would be distributed evenly in the cache. These values were chosen, so that a comparison to Infinispan 6 could be made. Infinispan 7 can handle a final result map with a much larger set of keys than is possible in Infinispan 6. The actual amount of heap size that is used for data will be larger due to backup copies, since the cluster is running in distributed mode.
- The MapReduceTask executes a word count against the cache values using mapper, reducer, combiner, and collator implementations. The collator returns the 10 most frequently occurring words in the cache data. The task used a distributed reduce phase and a shared intermediate cache. The MapReduceTask is executed 10 times against the data in the cache and the values are reported as an average of these durations.
From 1 to 8 nodes using a fixed amount of data and 30% of the heap
This test executes two word count executions on each cluster with an increasing number of nodes. The first execution uses an increasing amount of data equal to 30% of the total Java heap across the cluster (i.e. With one node, the data consumes 30% of 4 GB. With two nodes, the data consumes 30% of 8 GB, etc.), and the second execution uses a fixed amount of data, (1352 MB which is approximately 30% of 4 GB). Throughput is calculated by dividing the total amount of data processed by the Map/Reduce task by the duration. The following charts show the throughput as nodes are added to the cluster for these two scenarios:


From 1 to 8 nodes using different heap size percentages
This test executes the word count task using different percentages of heap size as nodes are added to the cluster. (5%, 10%, 15%, 20%, 25%, and 30%) Here are the throughput results for this test:
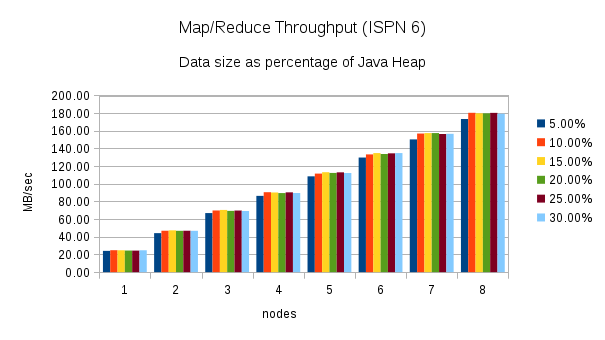

Once again, these charts show an increase in throughput when performing the same word count task using Infinispan 7. The chart for Infinispan 7 shows more fluctuation in the throughput across the different percentages of heap size. The throughput plotted in the Infinispan 6 chart is more consistent.
From 1 to 8 nodes using different value sizes
This test executes the word count task using 30% of the heap size and different cache value sizes as nodes are added to the cluster. (1KB, 2KB, 4KB, 8KB, 16KB, 32KB, 64KB, 128KB, 256KB, 512KB, 1MB, and 2MB) Here are the throughput results for this test:


Conclusion
The performance tests show that Infinispan 7 Map/Reduce improvements have increased the throughput and execution speed four to sixfold in some use cases. The changes have also allowed Infinispan 7 to process data sets that include larger intermediate results and produce larger final result maps. There are still areas of the Map/Reduce algorithm that need to be improved:
- The Map/Reduce algorithm should be self-tuning. The maxCollectorSize parameter controls the number of values that the collector holds in memory, and it is not trivial to determine the optimal value for a given scenario. The value is based on the size of the values in the cache and the size of the intermediate results. A user is likely to know the size of the cache values, but currently Infinispan does not report statistics about the intermediate results to the user. The Map/Reduce algorithm should analyze the environment at runtime and adjust the size of the collector dynamically.
- The fact that the throughput results vary with different value sizes needs to be investigated more closely. This could be due to the fact that the maxCollectorSize value used for these tests is not ideal for all value sizes, but there might be other causes for this behaviour.